[컴퓨터구조] Control Hazards
지난 포스트에 이어서, 이번엔 Control Hazard에 대해 알아보자.
Control Hazard
pipelined processor가 branch와 같은 control instruction을 수행할 때, branch 조건이 만족되었는지(taken) 혹은 만족되지 않았는지(not taken)에 따라 다음 PC 값이 결정된다. 그런데 branch instruction이 pipeline에 진입한 뒤 값들을 조건에 대입해 확인할 수 있는 것은 해당 inst가 적어도 ID stage에는 진입한 뒤의 일이다. 그동안 다음 PC의 값을 정확히 알 수 없는 문제를 Control Hazard라 한다.
그렇기 때문에 branch inst 직후의 PC를 프로세서가 예측하여 다음 inst를 넣게 되는데, 이를 branch prediction이라 한다. 예측이 틀렸을 경우에는 예측에 기반해 미리 pipeline에 넣었던 inst들을 전부 '무효화'하고, 올바른 PC 위치로 돌아가 다시 inst를 하나씩 pipeline에 진입시킨다.
예측이 틀릴 경우 손해를 보는 cycle의 수는 경우에 따라 다르다. 만약 Load-use와 같은 data hazard로 인해 조건 확인이 늦었는데 prediction이 틀린 것으로 밝혀지면, 꽤 많은 cycle의 손해를 보게 된다. 특히 이러한 문제는 pipeline이 매우 깊어지는 현대의 프로세서에서 더욱 두드러진다.
Static Branch Prediction
가장 단순한 prediction 방식은 모든 방향을 not taken으로 예측하는 것이다. 일단 branch 조건이 충족되지 않았다고 가정하고 PC를 무조건 PC+n으로 업데이트한 뒤, 틀린 것으로 밝혀지면 시정하는 것이다. 그러나 이러한 단순한 예측 방식은 branch penalty가 큰 경우 바람직하지 않다.
좀 더 나은 방식으로, branch instruction의 종류에 따른 branch 방향의 통계적 패턴을 이용해볼 수도 있다. 예를 들어, bne 0은 taken인 경우가 많고, beq 0은 그렇지 않다. (bne 0은 loop를 구현할 때 많이 쓰이니까) 이를 이용해 branch 중에서도 bne 0이 들어올 경우 taken으로 예측하는 prediction 방법이 있다. 이렇게 모든 branch instruction에 대해 '정적인' 예측 방식을 적용하는 것을 static prediction이라 한다.
Dynamic Branch Prediction
더 높은 정확도의 branch prediction을 위해, 이전 branch 방향들의 기록을 이용해서 다음 branch의 방향을 예측하는 기법을 dynamic prediction이라고 한다.
가장 단순한 dynamic prediction은, 가장 최근에 실행된 branch의 방향이 어디였는지를 이용하는 것이다. 만약 가장 최근 branch의 방향이 taken이었다면, 이번에도 taken일 것이라고 예측하는 것이다. 이 경우 prediction에 사용되는 state의 개수는 1개, 필요한 비트 수는 1이다.
조금 더 발전시키면, 가장 최근에 실행된 branch 방향 2개를 이용하여 예측하는 방법을 생각해볼 수 있다.
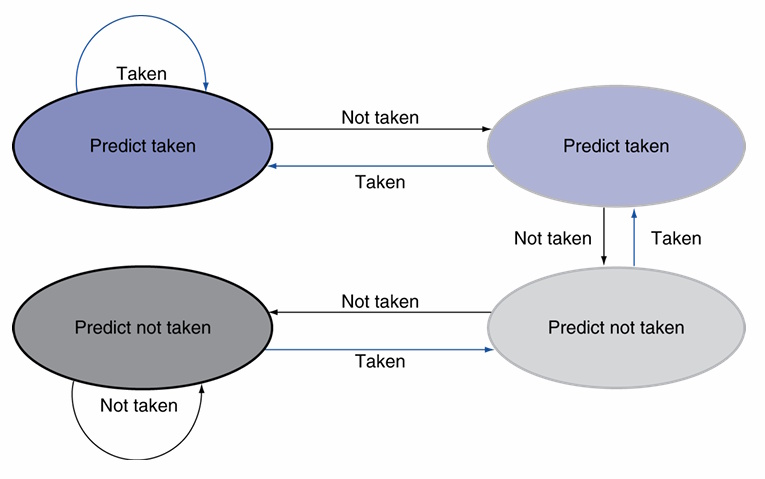
(사진: Patterson 교재)
이 방식에서는 4개의 state가 존재하고, 필요한 비트 수는 2이다. 오직 예측이 두 번 연속으로 틀렸을 때만 다음 예측을 바꾸게 된다.
2 bit prediction은 1 bit prediction에 비해 조금 더 좋다. (왜일까? 프로세서가 실행할 프로그램에 2중 루프가 들어있는 경우 branch prediction을 어떻게 할지 생각해 보자.)
Branch Target Buffer
위와 같이 dynamic prediction을 이용해 branch의 방향을 잘 예측하더라도, taken인 경우 다음 PC 값(target)을 계산하는 데에는 cycle이 더 소요될 수 있다.
이를 해결하기 위해, 최근 branch들의 target을 미리 기록해 두었다가, 다시 그 branch를 만났을 때 재사용하는 방식을 생각해볼 수 있다. Dynamic branch prediction에서 Branch Target Buffer (BTB) 라는 하드웨어 구조가 이러한 기능을 수행한다. 이는 최근에 실행한 branch inst의 주소를 index로, 해당 branch의 방향 기록을 value로 가지고 있는 표이다. (캐시와 비슷하다.)
BTB는 2^k개의 entry로 구성되어 있으며, k-bit index로 entry에 접근할 수 있는 구조이다. BTB의 한 entry는 다음으로 이루어져 있다.
[ Valid Bit ] [ Entry PC ] [ Predicted target PC ]
만약 프로세서가 branch inst를 만나면, 해당 branch inst에 해당하는 PC 값의 하위 k비트를 index로 삼아 BTB에서 검색을 수행한다.
그렇게 검색된 Entry에 대해 (1) Valid bit가 1이고, (2) PC가 Entry PC와 일치한다면 해당 Entry의 Predicted target PC 값을 가져와 branch prediction을 수행하게 된다. 만약 (1)과 (2) 조건이 만족되지 않는다면 해당 branch inst의 Target PC에 대한 유효한 기록이 BTB안에 존재하지 않는 것이다. 그럼 다음 PC를 그냥 PC+n으로 예측한다.
예측이 이루어진 뒤 branch의 조건 확인 및 target address 계산이 끝나면, 예측과 일치하는지 확인한다. 예측과 일치하지 않는다면 pipeline에서 잘못 들어간 inst들을 '무효화'하고, PC를 올바른 값으로 설정한 뒤, BTB의 Entry를 다음과 같이 업데이트한다.
[ 1 ] [ branch inst PC ] [ 실제로 계산된 target PC ]
instruction이 들어갈 수 있는 메모리 용량은 매우 크지만 BTB의 크기는 2^k개이다. 이로 인해 발생할 수 있는 index의 Collision 문제는 branch inst의 전체 PC 값을 태그(인식표)로써 Entry에 포함시켜 해결한다. 또한 프로그램이 실행되는 중에는 PC 값이 갑자기 크게 바뀌는 일이 드물기 때문에, 하위 k비트에 해당하는 주소들만을 저장해도 Collision이 일어나는 일이 자주 없으며 성능에 큰 문제가 없다. (이러한 특성을 Temporal Locality라고 한다.)
Branch History Table
Branch History Table (BHT)는 위의 2-bit prediction과 BTB의 아이디어가 모두 들어간 구조이다.
2-bit predictor를 하나의 entry로 삼아, 2^k개의 entry를 가진 table을 만드는 방식에 해당한다. 프로세서가 branch inst를 마주치면 PC의 하위 k비트를 index로 삼아 BHT entry를 검색하고, 해당 entry의 상태에 따라 branch 방향을 예측한다. 또한 실제 branch 방향이 계산된 후에 피드백을 통해 해당 entry의 상태를 업데이트한다.
References
- D. Patterson, J. Hennessy (2021). Computer Organization and Design: RISC-V edition (2nd ed). Morgan Kaufmann.
- Lecture Notes from SNU CSE (김지홍 교수님 강의노트)