[컴퓨터구조] Cache
이번 포스트에서는 Cache의 구현과 동작 원리에 대해 알아보겠다.
Direct Mapped Cache
프로세서에서 Cache에 있는 값을 어떻게 찾아 접근할까? 메모리에 있는 값을 요청하는 주소를 이용해서 캐시에도 접근할 수 있으면 좋을 것 같다. 데이터의 캐시에서의 위치가 메모리 주소에 의해 직접적으로 정해지는 캐시를 Direct Mapped Cache라 한다. Direct Mapped Cache에서는 주로 메모리 주소의 하위 비트들을 캐시의 index로 사용한다.
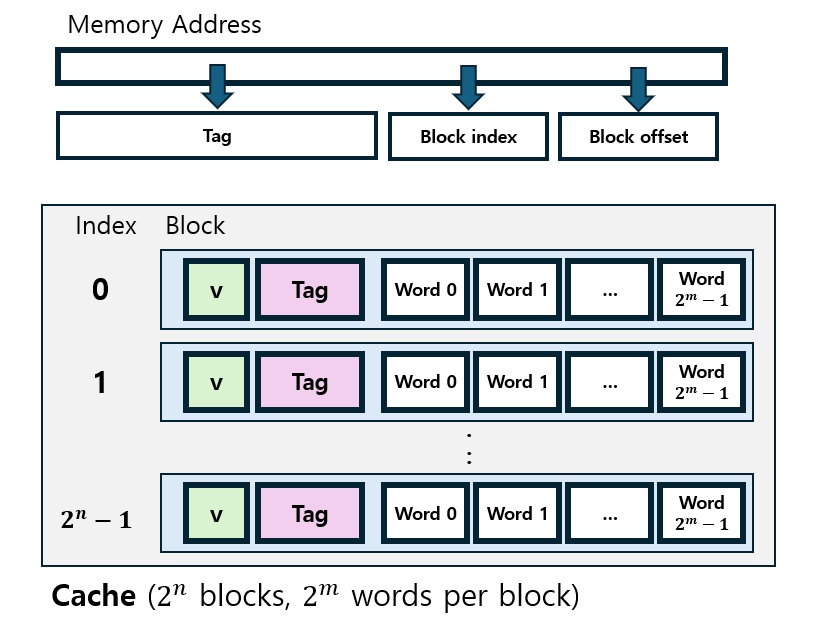
위 그림을 보면, 캐시는 Block이라는 단위로 이루어져 있다. 2^n개의 block이 있고 각 block에는 2^m개의 word가 저장되어 있다고 하자. 그럼 Memory address에서 하위 m비트를 block 안에서 word를 지정하는 offset으로, 그 다음 하위 n비트를 block을 지정하는 index로 삼을 수 있다.
그런데, 이렇게 하면 하위 n+m비트가 같은 복수의 메모리 주소들이 캐시에서 같은 자리에 배정되게 된다.겹치는 주소로 인해 엉뚱한 데이터 값에 접근하는 걸 막기 위해, 각 블록에는 메모리 주소의 상위 비트들을 고유한 Tag로 함께 저장하게 된다. 또, Valid bit도 저장한다. (캐시가 초기화된 후 아직 아무런 값도 저장되지 않았을 때 Invalid)
그래서 캐시 메모리 접근이 이루어질 때는 다음과 같은 과정이 일어난다.
(1) 주소로부터 Block index를 구하여 캐시에서 해당하는 Block을 찾는다.
(2) Valid bit를 확인한다. (Invalid일 시 Miss)
(3) Block의 tag와 주소의 tag가 일치하는지 확인한다. (불일치할 시 Miss)
(4) 주소로부터 Block offset을 구하여, 원하는 word에 접근한다. (Hit!)
Cache Hit가 발생한 경우, CPU는 원하는 값을 가지고 그대로 작업을 수행한다.
Cache Miss가 발생한 경우, CPU Pipeline을 stall한 뒤 하위 계층 메모리에 접근하여 해당하는 block을 가져와야 한다. 메모리에 접근해야 하는 만큼 시간이 더 걸리게 되고 이 추가되는 시간을 Miss penalty라 한다.
캐시에서 값을 읽는 것 말고, 쓰는 것은 어떻게 할까?
먼저 Write Hit이 발생한 경우부터 생각해 보자. 캐시에서만 값을 업데이트한다면 캐시에 저장된 값과 메모리에 저장된 값이 불일치하는 문제가 발생할 것이다. 이를 해결하기 위한 두 가지 방법이 있다.
첫 번째 방식은 Write-through로, 캐시에 데이터를 업데이트함과 동시에 그에 해당하는 메모리도 업데이트하는 것이다. 다만 이렇게 매번 메모리도 같이 접근하면 시간이 오래 걸리게 될 것이다. 그래서 Write buffer를 도입해, 업데이트해야 하는 메모리의 값들이 어느 정도 쌓이면 stall한 뒤 한번에 쓰는 방식으로 CPU의 속도 저하를 막을 수 있다.
두 번째 방식은 Write-Back으로, 캐시에 값을 쓰는 순간에는 캐시에서만 데이터를 업데이트하되, 그 블록이 메모리에서의 데이터와 달라졌다는 정보를 "Dirty bit"로 저장해 두는 것이다. 캐시에서 Dirty block이 있던 자리에 새로운 블록이 들어오게 되면, 그때 메모리를 업데이트한다.
이제 Write Miss가 발생한 경우를 생각해 보자. Write-Back 방식으로 값을 쓴다면, 주로 하위 메모리에 접근하여 해당 블록을 캐시로 가져온 후 거기에 업데이트한다. 그러나 캐시는 건드리지 않고, 메모리에서만 업데이트하는 방식도 좋은 방법일 수 있다. (Write around라고 한다.) 프로그램이 시작될 때 메모리 값을 읽지는 않고 계속 쓰기(변수 초기화)만 하는 경우가 있기 때문이다.
Block Size Consideraitons
앞서 Block은 캐시에서 데이터를 저장하는 단위임을 설명했었다. 캐시가 메모리에서 Block을 단위로 한번에 데이터를 가져오는 것은 Spatial Locality에 기반한다. 한번에 주변 주소에 해당하는 데이터까지 가져온다면 miss 발생을 줄일 수 있는 것이다. 그렇다면, Block size (한 block에 몇 개의 word가 들어가는지)를 어떻게 설정하는 것이 좋을까?
Block size가 커지면...
- spatial locality에 의해 miss rate은 줄어들 것이다.
- 그러나, Cache 전체의 크기는 변하지 않는다면 Block size가 커졌을 때 Block들의 수 자체는 줄어들게 된다. 이로 인해 miss rate이 오히려 올라가는 효과가 발생할 수 있다.
- Write-back 방식에서, Block이 크면 작은 부분만 값을 바꿔도 많은 부분이 Dirty block이 되어 비효율적이다. (Pollution)
- Miss 시 메모리에서 가져와야 하는 데이터의 양이 많아지므로 Miss penalty가 커진다.
따라서 Block size가 커지면 항상 좋은 것은 아니고, tradeoff가 있다.
이중 4번째 효과인 Miss penaly 증가 문제는 다음과 같은 최적화 방법으로 완화할 수 있다.
Early Restart: Miss 발생 시 Block을 전부 가져오기까지 기다리지 않고, 필요로 하는 word가 도착한 즉시 CPU 파이프라인을 재시작한다.
Requested Word First (Critical Word First): Miss 발생 시 필요로 하는 word부터 메모리에서 캐시로 보낸다.
References
- D. Patterson, J. Hennessy (2021). Computer Organization and Design: RISC-V edition (2nd ed). Morgan Kaufmann.
- Lecture Notes from SNU CSE (김지홍 교수님 강의노트)